|
En este último número de la revista hacemos una promoción 2x1. Llévese los dos últimos artículos del curso de ensamblador por el precio de uno. Lenguaje Ensamblador del Z80 (IV) La pila y las llamadas a subrutinas Los 2 temas que vamos a tratar hoy, la pila por un lado y las llamadas a subrutinas por otro, están íntimamente relacionados. Como veremos, la pila del Spectrum es aquello que permite la utilización de rutinas a las que pasaremos parámetros, y que volverán al punto donde fueron llamadas tras su ejecución. La pila del Spectrum Hoy vamos a tratar una de las cosas más importantes del microprocesador Z80: la pila o Stack (en inglés). La pila, teóricamente, es una porción de memoria donde se pueden almacenar valores de 16 bits. Su nombre viene del hecho que los datos se almacenan unos encima de otros, como en una pila de platos. Cuando almacenamos un nuevo plato en una pila, lo dejamos encima del todo de la misma, sobre el plato anterior. Cuando queremos coger un plato, cogemos el plato más alto, el que está en la parte más alta de la pila. Las pilas son una estructura de datos conocida como estructura LIFO: Last In, First Out: el último que entró es el primero que sale. En nuestro ejemplo de los platos, efectivamente cuando retiramos un plato (el primero que sale) extraemos el que está arriba del todo (el último que habíamos dejado). En una pila de ordenador (como en nuestra pila de datos) sólo podemos trabajar con el dato (o plato) que está arriba del todo de la pila: no podemos extraer uno de los platos intermedios. Sólo podemos apilar un plato nuevo y desapilar el plato apilado arriba del todo de la pila.
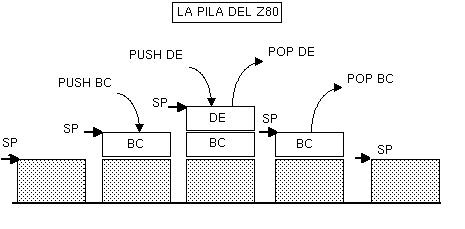
La pila del Spectrum no es de platos sino de valores numéricos de 16 bits. Introducimos
valores y sacamos valores mediante 2 instrucciones concretas: PUSH
Por ejemplo, podemos guardar el valor que contiene un registro en la pila si tenemos que hacer operaciones con ese registro para así luego recuperarlo tras realizar la tarea que tengamos que realizar:
La instrucción PUSH BC lo que ha hecho es introducir en memoria, en lo alto de la pila, el valor 1000, que recuperamos posteriormente con el POP BC. La realidad es que el Spectrum no tiene una zona de memoria especial o aislada de la RAM dedicada a la pila. En su lugar se utiliza la misma RAM del Spectrum (0-65535). El Z80 tiene un registro conocido como SP (Stack Pointer), o puntero de pila, que es un registro de 16 bits que contiene una dirección de memoria. Esa dirección de memoria es la cabeza de la pila: apunta al próximo lugar donde almacenaremos un dato (al hueco donde guardaremos el próximo plato). La peculiaridad de la pila del Spectrum es que crece hacia abajo, en lugar de hacia arriba. Veamos un ejemplo práctico:
Supongamos que SP (puntero de pila) apunta a 65535 (la última posición de la memoria). Hagamos una serie de PUSHes y POPs de registros de 16 bits. Sea el siguiente programa:
Si ahora hacemos:
Lo que estaremos haciendo es:
Con lo que el contenido de la memoria sería:
Si a continuación hacemos otro PUSH:
Lo que estaremos haciendo es:
Con lo que el contenido de las celdillas de memoria sería:
Si ahora hacemos un POP:
Lo que hacemos es:
Y la memoria queda, de nuevo, como:
Como podemos ver, PUSH va apilando valores, haciendo decrecer el valor de SP, mientras que POP recupera valores, haciendo crecer (en 2 bytes, 16 bits) el valor de SP. PUSH y POP Así pues, podemos hacer PUSH y POP de los siguientes registros:
Lo que hacen PUSH y POP, tal y como funciona la pila, es:
Nótese cómo la pila se decrementa ANTES de poner los datos en ella, y se incrementa DESPUES de sacar datos de la misma. Esto mantiene siempre SP apuntando al TOS (Top Of Stack).
Nótese que también podemos apilar y desapilar AF. De hecho, es una forma de manipular los bits del registro F (hacer PUSH BC con un valor determinado, por ejemplo, y hacer un POP AF). Utilidad de la pila del Spectrum La pila resulta muy útil para gran cantidad de tareas en programas en ensamblador. Veamos algunos ejemplos:
Esto incluye, por ejemplo, el almacenaje del valor de BC en los bucles cuando necesitamos operador con B, C o BC:
En este sentido, también podremos anidar 2 o más bucles que usen el registro B o BC con PUSH y POPs entre ellos. Supongamos un bucle BASIC del tipo:
En ensamblador podríamos hacer:
Hay que tener en cuenta que PUSH y POP implican escribir en memoria (en la dirección apuntada por SP), por que siempre serán más lentas que guardarse el valor actual de B en otro registro:
No obstante, en múltiples casos nos quedaremos sin registros libres donde guardar datos, por lo que la pila es una gran opción. No hay que obsesionarse con no usar la pila porque implique escribir en memoria. A menos que estemos hablando de una rutina muy muy crítica, que se ejecute muchas veces por cada fotograma de nuestro juego, PUSH y POP serán las mejores opciones para preservar valores.
Recordad también que tenéis instrucciones de intercambio (EX) que permiten manipular la pila. Hablamos de:
Los peligros de la pila Pero como todo arma, las pilas también tienen un doble filo. Mal utilizada puede dar lugar a enormes desastres en nuestros programas. Veamos algunos de los más habituales:
Veamos algunos ejemplos de errores con la pila. Empecemos con el típico PUSH del cual se nos olvida hacer POP:
También hay que tener cuidado con los bucles:
En ese código hacemos múltiples PUSHes pero un sólo POP. Probablemente, en realidad, queremos hacer lo siguiente:
Y una curiosidad al respecto de la pila y la sentencia CLEAR de BASIC: en el fondo, lo que realiza esta función es cambiar el valor de la variable del sistema RAMTOP, lo que implica cambiar el valor de SP. Así, con CLEAR XXXX, ponemos la pila colgando de la dirección de memoria XXXX, asegurándonos de que BASIC no pueda hacer crecer la pila de forma que machaque código máquina que hayamos cargado nosotros en memoria. Si, por ejemplo, vamos a cargar todo nuestro código a partir de 50000, en nuestro cargador BASIC haremos un CLEAR 49999, de forma que BASIC no podrá tocar ninguna dirección de memoria por encima de este valor. Rutinas: CALL y RET Ya de por sí el lenguaje ensamblador es un lenguaje de listados largos y enrevesados, y donde teníamos 10 líneas en BASIC podemos tener 100 ó 1000 en ensamblador. Lo normal para hacer el programa más legible es utilizar bloques de código que hagan unas funciones concretas y a los cuales podamos llamar a lo largo de nuestro programa. Esos bloques de código son las funciones o subrutinas. Las subrutinas son bloques de código máquina a las cuales saltamos, hacen su tarea asignada, y devuelven el control al punto en que fueron llamadas. A veces, esperan recibir los registros con una serie de valores y devuelven registros con los valores resultantes. Por ejemplo:
Nuestra función/subrutina de ejemplo espera obtener en A un valor, y devuelve el resultado de su ejecución en B. Antes de llamar a esta rutina, nosotros deberemos poner en A el valor sobre el que actuar, y posteriormente interpretar el resultado (sabiendo que lo tenemos en B). Pero, ¿cómo llamamos a las subrutinas y volvemos de ellas? Podéis pensar en nuestro ejemplo anterior y la orden JP:
En este caso, cargaríamos A con el valor 35, saltaríamos a la subrutina, sumaríamos 10 a A (pasando a valer 45), haríamos B = 45, y volveríamos al lugar posterior al punto de llamada. Pero ¿qué pasaría si quisieramos volver a llamar a la subrutina desde otro punto de nuestro programa? Que sería inviable, porque nuestra subrutina acaba con un JP volver1 que no devolvería la ejecución al punto desde donde la hemos llamado, sino a volver1.
Para evitar ese enorme problema es para lo que se usa CALL y RET. Uso de CALL y RET CALL es, en esencia, similar a JP, salvo porque antes de realizar el salto, introduce en la pila (PUSH) el valor del registro PC (Program Counter, o contador de programa), el cual una vez leído y decodificado el CALL apunta a la siguiente instrucción tras el mismo. ¿Y para qué sirve eso? Para que lo aprovechemos dentro de nuestra subrutina con RET. RET lee de la pila la dirección que introdujo CALL y salta a ella. Así, cuando acaba nuestra función, el RET devuelve la ejecución a la instrucción siguiente al CALL que hizo la llamada. Son, por tanto, el equivalente ensamblador de GO SUB y RETURN en BASIC (o más bien se debería decir que GO SUB y RETURN son la implantación en BASIC de estas instrucciones del microprocesador).
En esta ocasión, cuando ejecutamos el primer CALL, se introduce en la pila el valor de PC, que se corresponde exáctamente con la dirección de memoria donde estaría ensamblada la siguiente instrucción (LD A, 50). El CALL cambia el valor de PC al de la dirección de SUMA_A_10, y se continúa la ejecución dentro de la subrutina. Al acabar la subrutina encontramos el RET, quien extrae de la pila el valor de PC anteriormente introducido, con lo que en el siguiente ciclo de instrucción del microprocesador, el Z80 leerá, decodificará y ejecutará la instrucción LD A, 50, siguiendo el flujo del programa linealmente desde ahí. Con la segunda llamada a CALL ocurriría lo mismo, pero esta vez lo que se introduce en la pila es la dirección de memoria en la que está ensamblada la instrucción LD C, B. Esto asegura el retorno de nuestra subrutina al punto adecuado. Al hablar de la pila os contamos lo importante que era mantener la misma cantidad de PUSH que de POPs en nuestro código. Ahora entenderéis por qué: si dentro de una subrutina hacéis un PUSH que no elimináis después con un POP, cuando lleguéis al RET éste obtendrá de la pila un valor que no será el introducido por CALL, y saltará allí. Por ejemplo:
Aquí RET sacará de la pila 0000h, en lugar de la dirección que introdujo CALL, y saltará al inicio del a ROM, produciendo un bonito reset. Ni call ni RET afectan a la tabla de flags del registro F.
Saltos y retornos condicionales Una de las peculiaridades de CALL y RET es que tienen instrucciones condicionales con respecto al estado de los flags, igual que JP cc o JR cc, de forma que podemos condicionar el SALTO (CALL) o el retorno (RET) al estado de un determinado flag. Para eso, utilizamos las siguientes instrucciones:
Por ejemplo, supongamos que una de nuestras subrutinas tiene que comprobar que uno de los parámetros que le pasamos, BC, no sea 0.
Del mismo modo, el uso de CALL condicionado al estado de flags (CALL Z, CALL NZ, CALL M, CALL P, etc) nos permitirá llamar o no a funciones según el estado de un flag. Al igual que CALL y RET, sus versiones condicionales no afectan al estado de los flags.
Pasando parametros a rutinas Ahora que ya sabemos crear rutinas y utilizarlas, vamos a ver los 3 métodos que hay para pasar y devolver parámetros a las funciones. Método 1: Uso de registros Este método consiste en modificar unos registros concretos antes de hacer el CALL a nuestra subrutina, sabiendo que dicha subrutina espera esos registros con los valores sobre los que actuar. Asímismo, nuestra rutina puede modificar alguno de los registros con el objetivo de devolvernos un valor. Por ejemplo:
Antes de hacer la llamada a MULTIPLICA, tendremos que cargar en H y en E los valores que queremos multiplicar, de modo que si estos valores están en otros registros o en memoria, tendremos que moverlos a H y a E. Además, sabemos que la salida nos será devuelta en HL, con lo que si dicho registro (especialmente L en nuestro caso, ya que H es un parámetro de entrada) contiene algún valor importante, deberemos preservarlo previamente. Con este tipo de funciones resulta importantísimo realizarse cabeceras de comentarios explicativos, que indiquen:
Con este tipo de paso de parámetros tenemos el mayor ahorro y la mayor velocidad: no se accede a la pila y no se accede a la memoria, pero por contra tenemos que tenerlo todo controlado. Tendremos que saber en cada momento qué parámetros de entrada y de salida utiliza (de ahí la importancia del comentario explicativo, al que acudiremos más de una vez cuando no recordemos en qué registros teníamos que pasarle los datos de entrada), y asegurarnos de que ninguno de los registros extra que modifica están en uso antes de llamar a la función, puesto que se verán alterados. Si no queremos que la función modifique muchos registros además de los de entrada y salida, siempre podemos poner una serie de PUSH y POP en su inicio y final, al estilo:
En funciones que no sean críticas en velocidad, es una buena opción porque no tendremos que preocuparnos por el estado de nuestros registros durante la ejecución de la subrutina: al volver de ella tendrán sus valores originales (excepto aquellos de entrada y salida que consideremos necesarios). No nos olvidemos de que en algunos casos podemos usar el juego de registros alternativos (EX AF, AF', EXX) para evitar algún PUSH o POP. Método 2: Uso de localidades de memoria Aunque no es una opción rápida, sí que es bastante efectivo y sencillo el uso de variables o posiciones de memoria para pasar y recoger parámetros de funciones. Nos ahorra el uso de muchos registros, y hace que podamos usar dentro de las funciones prácticamente todos los registros. Se hace especialmente útil usando el juego de registros alternativos. Por ejemplo:
Este es un ejemplo exagerado donde todos los parámetros se pasan en variables, pero lo normal es usar un método mixto entre este y el anterior, pasando cosas en registros excepto si nos quedamos sin ellos (por que una función requiere muchos parámetros, por ejemplo), de forma que algunas cosas las pasamos con variables de memoria. Método 3: Uso de la pila (método C) El tercer método es el sistema que utilizan los lenguajes de alto nivel para pasar parámetros a las funciones: el apilamiento de los mismos. Este sistema no se suele utilizar en ensamblador, pero vamos a comentarlo de forma que os permita integrar funciones en ASM dentro de programas escritos en C, como los compilables con el ensamblador Z88DK. En C (y en otros lenguajes de programación) los parámetros se insertan en la pila en el orden en que son leídos. La subrutina debe utilizar el registro SP (una copia) para acceder a los valores apilados en orden inverso. Estos valores son siempre de 16 bits aunque las variables pasadas sean de 8 bits (en este caso ignoraremos el byte que no contiene datos, el segundo). Veamos unos ejemplos:
No tenemos que preocuparnos por hacer PUSH y POP de los registros para preservar su valor dado que C lo hace automáticamente antes y después de cada #asm y #endasm. El problema es que conforme crece el número de parámetros apilados, es posible que tengamos que hacer malabarismos para almacenarlos, dado que no podemos usar HL (es nuestro puntero a la pila en las lecturas). Veamos el siguiente ejemplo con 3 parámetros, donde tenemos que usar PUSH para guardar el valor de DE y EX DE, HL para acabar asociando el valor final a HL:
La manera de leer bytes (char) pulsados en C es de la misma forma que leemos una palabra de 16 bits, pero ignorando la parte alta. En realidad, como la pila es de 16 bits, el compilador convierte el dato de 8 bits en uno de 16 (rellenando con ceros) y pulsa este valor:
En ocasiones, es posible que incluso tengamos que utilizar variables auxiliares de memoria para guardar datos:
Por contra, para devolver valores no se utiliza la pila (dado que no podemos tocarla), sino que se utiliza un determinado registro. En el caso de Z88DK, se utiliza el registro HL. Si la función es de tipo INT o CHAR en cuanto a devolución, el valor que dejemos en HL será el que se asignará en una llamada de este tipo:
Hemos considerado importante explicar este tipo de paso de parámetros y devolución de valores porque nos permite integrar nuestro código ASM en programas en C. Integracion de ASM en Z88DK Para aprovechar esta introducción de uso de ASM en z88dk, veamos el código de alguna función en C que use ASM internamente y que muestre, entre otras cosas, la lectura de parámetros de la pila, el acceso a variables del código C, el uso de etiquetas, o la devolución de valores.
Si tenéis curiosidad por ver el funcionamiento de esta rutina de Fade (fundido), podéis verla integramente en ASM en el fichero fade.asm. Un detalle a tener en cuenta, en Z88DK se soporta EX AF, AF, mientras que pasmo requiere poner la comilla del shadow-register: EX AF, AF'.
En la anterior captura podéis ver el aspecto de uno de los pasos del fundido. La importancia de usar subrutinas Usar subrutinas es mucho más importante de lo que parece a simple vista: nos permite organizar el programa en unidades o módulos funcionales que cumplen una serie de funciones específicas, lo que hace mucha más sencilla su depuración y optimización. Si en el menú de nuestro juego estamos dibujando una serie de sprites móviles, y también lo hacemos a lo largo del juego, resulta absurdo construir 2 bloques de código, uno para mover los sprites del menú y otro para los del juego. Haciendo esto, si encontramos un error en una de las 2 rutinas, o realizamos una mejora, deberemos corregirlo en ambas. Por contra, si creamos una subrutina, digamos, DrawSprite, que podamos llamar con los parámetros adecuados en ambos puntos del programa, cualquier cambio, mejora o corrección que realicemos en DrawSprite afectará a todas las llamadas que le hagamos. También reducimos así el tamaño de nuestro programa (y con él el tiempo de carga del mismo), las posibilidades de fallo, y la longitud del listado (haciéndolo más legible y manejable). Aunque no sea el objetivo de esta serie de artículos, antes de sentarse a teclear, un buen programador debería coger un par de folios de papel y hacer un pequeño análisis de lo que pretende crear. Este proceso, la fase de diseño, define qué debe de hacer el programa y, sobre todo, una división lógica de cuáles son las principales partes del mismo. Un sencillo esquema en papel, un diagrama de flujo, identificar las diferentes partes del programa, etc. El proceso empieza con un esbozo muy general del programa, que será coincidente con la gran mayoría de los juegos: inicialización de variables, menú (que te puede llevar bien a las opciones o bien al juego en sí), y dentro del juego, lectura de teclado/joystick, trazado de la pantalla, lógica del juego, etc. Después, se teclea un programa vacío que siga esos pasos, pero que no haga nada; un bucle principal que tenga un aspecto parecido a:
Tras esto, ya tenemos el esqueleto del programa. Y ahora hay que rellenar ese esqueleto, y la mejor forma de hacerlo es aprovechar esa modularidad que hemos obtenido con ese diseño en papel. Por ejemplo, supongamos que nuestro juego tiene que poder dibujar sprites y pantallas hechas a bases de bloques que se repiten (tiles). Gracias a nuestro diseño, sabemos que necesitamos una rutina que imprima un sprite, una rutina que dibuje un tile y una rutina que dibuje una pantalla llena de tiles. Pues bien, creamos un programa en ASM nuevo, desde cero, y en él creamos una función DrawSprite que acepte como parámetros la dirección origen de los datos del Sprite, y las posiciones X e Y donde dibujarlo, y la realizamos. En este nuevo programa, pequeño, sencillo de leer, realizamos todo tipo de pruebas:
Gracias a esto, podremos probar nuestra nueva rutina y trabajar con ella limpiamente y en un fichero de programa pequeño. Cuando la tenemos lista, basta con copiarla a nuestro programa principal y ya sabemos que la tenemos disponible para su uso con CALL. Así, vamos creando diferentes rutinas en un entorno controlado y testeable, y las vamos incorporando a nuestro programa. Si hay algún bug en una rutina y tenemos que reproducirlo, podemos hacerlo en nuestros pequeños programas de prueba, evitando el típico problema de tener que llegar a un determinado punto de nuestro programa para chequear una rutina, o modificar su bucle principal para hacerlo. Además, el definir de antemano qué tipo de subrutinas necesitamos y qué parámetros deben aceptar o devolver permite trabajar en equipo. Si sabes que necesitarás una rutina que dibuje un sprite, o que lea el teclado y devuelva la tecla pulsada, puedes decir los registros de entrada y los valores de salida que necesitas, y que la realice una segunda persona y te envíe la rutina lista para usar. En ocasiones una excesiva desgranación del programa en módulos más pequeños puede dar lugar a una penalización en el rendimiento, aunque no siempre es así. Por ejemplo, supongamos que tenemos que dibujar un mapeado de 10×10 bloques de 8×8 pixeles cada uno. Si hacemos una función de que dibuja un bloque de 8×8, podemos llamarla en un bucle para dibujar nuestros 10×10 bloques. Hay gente que, en lugar de esto, preferirá realizar una función específica que dibuje los 10×10 bloques dentro de una misma función. Esto es así porque de este modo te evitas 100 CALLs (10×10) y sus correspondientes RETs, lo cual puede ser importante en una rutina gráfica que se ejecute X veces por segundo. Por supuesto, en muchos casos tendrán razón, en ciertas ocasiones hay que hacer rutinas concretas para tareas concretas, aún cuando puedan repetir parte de otro código que hayamos escrito anteriormente, con el objetivo de evitar llamadas, des/apilamientos u operaciones innecesarias en una función crítica. Pero si, por ejemplo, nosotros sólo dibujamos la pantalla una vez cuando nuestro personaje sale por el borde, y no volvemos a dibujar otra hasta que sale por otro borde (típico caso de juegos sin scroll que muestran pantallas completas de una sóla vez), vale la pena el usar funciones modulares dado que unos milisegundos más de ejecución en el trazado de la pantalla no afectarán al desarrollo del juego. Al final hay que llegar a un compromiso entre modularidad y optimización, en algunos casos nos interesará desgranar mucho el código, y en otros nos interesará hacer funciones específicas. Y esa decisión no deja de ser, al fin y al cabo, diseño del programa. En cualquier caso, el diseño nos asegura que podremos implementar nuestro programa en cualquier lenguaje y en cualquier momento. Podremos retomar nuestros papeles de diseño 3 meses después y, pese a no recordar en qué parte del programa estábamos, volver a su desarrollo sin excesivas dificultades. Una de las cosas más complicadas de hacer un juego es el pensar por dónde empezar. Todo este proceso nos permite empezar el programa por la parte del mismo que realmente importa. Todos hemos empezado alguna vez a realizar nuestro juego por el menú, perdiendo muchas horas de trabajo para descubrir que teníamos un menú, pero no teníamos un juego, y que ya estábamos cansados del desarrollo sin apenas haber empezado. Veamos un ejemplo: suponiendo que realizamos, por ejemplo, un juego de puzzles tipo Tetris, lo ideal sería empezar definiendo dónde se almacenan los datos del area de juego, hacer una función que convierta esos datos en imágenes en pantalla, y realizar un bucle que permita ver caer la pieza. Después, se agrega control por teclado para la pieza y se pone la lógica del juego (realización de líneas al tocar suelo, etc). Tras esto, ya tenemos el esqueleto funcional del juego y podemos añadir opciones, menúes y demás. Tendremos algo tangible, funcional, donde podemos hacer cambios que implican un inmediato resultado en pantalla, y no habremos malgastado muchas horas con un simple menú. Por otra parte, el diseñar correctamente nuestro programa y desgranarlo en piezas reutilizables redundará en nuestro beneficio no sólo actual (con respecto al programa que estamos escribiendo) sino futuro, ya que podremos crearnos nuestras propias bibliotecas de funciones que reutilizar en futuros programas. Aquella rutina de dibujado de Sprites, de zoom de pantalla o de compresión de datos que tanto nos costó programar, bien aislada en una subrutina y con sus parámetros de entrada y salida bien definidos puede ser utilizada directamente en nuestros próximos programas simplemente copiando y pegando el código correspondiente. Más aún, podemos organizar funciones con finalidades comunes en ficheros individuales. Tendremos así nuestro fichero / biblioteca con funciones gráficas, de sonido, de teclado/joystick, etc. El ensamblador PASMO nos permite incluir un fichero en cualquier parte de nuestro código con la directiva INCLUDE. Así, nuestro programa en ASM podría comenzar (o acabar) por algo como:
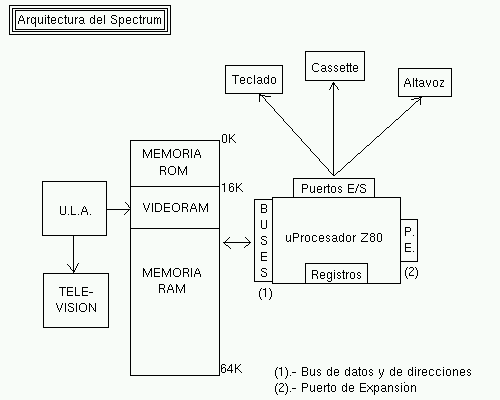
Esto contribuye a reducir fallos en la codificación, hacer más corto el listado general del programa, y, sobre todo, reduce el tiempo de desarrollo. Lenguaje Ensamblador del Z80 (V) Puertos de E/S y Tabla de Opcodes En este capítulo se introducirán las instrucciones IN y OUT para la exploración de los puertos del microprocesador, mostrando cómo el acceso a dichos puertos nos permitirá la gestión de los diferentes dispositivos conectados al microprocesador (teclado, altavoz, controladora de disco, etc...). Finalmente, para acabar con la descripción del juego de instrucciones del Z80 veremos algunos ejemplos de opcodes no documentados, y una tabla-resumen con la mayoría de instrucciones, así como sus tiempos de ejecución y tamaños. Los puertos E/S Como ya vimos en su momento, el microprocesador Z80 se conecta mediante los puertos de entrada/salida de la CPU a los periféricos externos (teclado, cassette y altavoz de audio), pudiendo leer el estado de los mismos (leer del teclado, leer del cassette) y escribir en ellos (escribir en el altavoz para reproducir sonido, escribir en el cassette) por medio de estas conexiones conocidas como "I/O Ports".
IN y OUT Ya conocemos la existencia y significado de los puertos y su conexión con el microprocesador. Sólo resta saber: ¿cómo accedemos a un puerto tanto para leer como para escribir desde nuestros programas en ensamblador? La respuesta la tienen los comandos IN y OUT del Z80. Comenzaremos con IN, que nos permite leer el valor de un puerto ya sea directamente, o cargado sobre el registro BC: IN registro, (C) Leemos el puerto "BC" y ponemos su contenido en el registro especificado. En realidad, pese a que teóricamente el Spectrum sólo tiene acceso a puertos E/S de 8 bits (0-255), para acceder a los puertos, IN r, (C) pone todo el valor de BC en el bus de direcciones.IN A, (puerto) Leemos el puerto "A*256 + Puerto" y ponemos su contenido en A. En esta ocasión, el Spectrum pone en el bus de direcciones el valor del registro de 16 bits formado por A y (puerto) (en lugar de BC). Por ejemplo, estas 2 lecturas de puerto (usando los 2 formatos de la instrucción IN vistos anteriormente) son equivalentes:
Aunque la instrucción de la "Forma 1" hable del puerto C, en realidad el puerto es un valor de 16 bits y se carga en el registro BC. De la misma forma, podemos escribir un valor en un puerto con sus equivalentes "OUT": OUT (puerto), A Escribimos en "puerto" (valor de 8 bits) el valor de A. OUT (C), registro Escribimos en el puerto "C" el valor contenido en "registro" (aunque se pone el valor de BC en el bus de direcciones). Curiosamente, como se explica en el excelente documento "//The Undocumented Z80 Documented//" (que habla de las funcionalidades y opcodes no documentados del Z80), los puertos del Spectrum son oficialmente de 8 bits (0-255) aunque realmente se pone o bien BC o bien (A*256)+PUERTO en el bus de direcciones, por lo que en el fondo se pueden acceder a todos los 65536 puertos disponibles. La forma en que estas instrucciones afectan a los flags es la siguiente:
Aunque entre los 2 formatos OUT no debería haber ninguna diferencia funcional, cabe destacar que "OUT (N), A" es 1 t-estado o ciclo de reloj más rápida que "OUT (C), A", tardando 11 y 12 t-estados respectivamente. Instrucciones de puerto repetitivas e incrementales Al igual que LD carga un valor de un origen a un destino, y tiene sus correspondientes instrucciones incrementales (LDI "carga e incrementa", LDD "carga y decrementa") o repetitivas (LDIR "carga, incrementa y repite BC veces", LDDR "carga, decrementa, y repite BC veces"), IN y OUT tienen sus equivalentes incrementales y repetidores. Así:
Y sus versiones repetitivas INDR, INIR, OTDR y OTIR, que realizan la misma función que sus hermanas incrementales, repitiéndolo hasta que BC sea cero. Las afectaciones de flags de estas funciones son las siguientes: Flags:
Algunos puertos E/S comunes Para terminar con el tema de los puertos de Entrada y Salida, vamos a hacer referencia a algunos puertos disponibles en el Sinclair Spectrum (algunos de ellos sólo en ciertos modelos). Como veremos en capítulo dedicado al teclado, existe una serie de puertos E/S que acceden directamente a la lectura del estado de las diferentes teclas de nuestro Spectrum. Leyendo del puerto adecuado, y chequeando en la respuesta obtenida el bit concreto asociado a la tecla que queremos consultar podremos conocer si una determinada tecla está pulsada (0) o no pulsada (1), como podemos ver en el siguiente ejemplo:
El anterior ejemplo lee constantemente el puerto $DFFE a la espera de que el bit 0 de la respuesta obtenida de dicha lectura sea 0, lo que quiere decir que la tecla "p" ha sido pulsada. Aunque los veremos en su momento en profundidad, estos son los puertos asociados a las diferentes filas de teclas:
El bit 6 de los puertos que hemos visto para el teclado tiene un valor aleatorio, excepto cuando se pulsa PLAY en el cassette, y es a través de dicho bit de donde podremos obtener los datos a cargar. La escritura en el puerto 00FEh permite acceder al altavoz (bit 4) y a la señal de audio para grabar a cinta (bit 3). Los bits 0, 1 y 2 controlan el color del borde, como podemos ver en el siguiente ejemplo:
El puerto 7FFDh gestiona la paginación en los modos de 128K, permitiendo cambiar el modelo de páginas de memoria (algo que no vamos a ver en este capítulo). Los puertos BFFDh y FFFDh gestionan el chip de sonido en aquellos modelos que dispongan de él, así como el RS232/MIDI y el interfaz AUX. Finalmente, el puerto 0FFDh gestiona el puerto paralelo de impresora, y los puertos 2FFDh y 3FFDh permiten gestionar la controladora de disco en aquellos modelos de Spectrum que dispongan de ella. Podéis encontrar más información sobre los puertos de Entrada y Salida en el capítulo 8 sección 23 del manual del +2A y +3, disponible online en World Of Spectrum. Tabla de instrucciones, ciclos y tamaños A continuación se incluye una tabla donde se hace referencia a las instrucciones del microprocesador Z80 (campo Mnemonic), los ciclos de reloj que tarda en ejecutarse (campo Clck), el tamaño en bytes de la instrucción codificada (Siz), la afectación de Flags (SZHPNC), el opcode y su descripción en cuanto a ejecución. La tabla forma parte de un documento llamado "The Complete Z80 OP-Code Reference", de Devin Gardner.
La leyenda para interpretar esta tabla es la siguiente:
Unos apuntes sobre esta tabla: 1.- En instrucciones como "ADC A, r" podemos ver una defición del OPCODE como "88+rb". En este caso, el opcode final se obtendría sumando a "88h" un valor de 0 a 7 según el registro al que nos referimos:
Por ejemplo, "ADC A, B" se codificaría en memoria como "88+0=88". 2.- En los saltos hay 2 tiempos de ejecución diferentes (por ejemplo, 10/1). En este caso el valor más alto (10) son los t-estados o ciclos que toma la instrucción cuando el salto se realiza, y el más bajo (1) es lo que tarda la instrucción cuando no se salta al destino. Como véis, a la hora de programar una rutina que tenga saltos o bifurcaciones, es interesante programarla de forma que el caso más común, el que se produzca la mayoría de las veces, no produzca un salto. 3.- La descripción de las afectaciones de flags son las siguientes:
Instrucciones no documentadas del Z80 En Internet podemos encontrar gran cantidad de documentación acerca del Z80 y su juego de instrucciones, incluyendo las especificaciones oficiales del microprocesador Z80 de Zilog. No obstante, existen una serie de instrucciones u opcodes que el microprocesador puede ejecutar y que no están detallados en la documentación oficial de Zilog. Con respecto a esto, tenemos la suerte de disponer de algo que los programadores de la época del Spectrum no tenían: una descripción detallada de las instrucciones no documentadas del Z80. Aunque la mayoría son instrucciones repetidas de sus versiones documentadas, hay algunas instrucciones curiosas y a las que tal vez le podamos sacar alguna utilidad.¿Por qué existen estos opcodes y no fueron documentados? Supongo que algunos de ellos no fueron considerados como "merecedores de utilidad alguna" y los ingenieros de Zilog no los documentaron, o tal vez sean simplemente un resultado no previsto de la ejecución del Z80 porque los diseñadores no pensaron que al microprocesador pudieran llegarle dichos códigos. El caso es que para el microprocesador existen "todos" los opcodes, otra cosa es qué haga al leerlos y decodificarlos. En este caso algunos de ellos realizan funciones válidas mientras que otros son el equivalente a ejecutar 2 instrucciones NOP, por ejemplo. ¿Cuál es la utilidad de estas instrucciones para los programadores? Para ser sinceros, como programadores con un ensamblador o un ensamblador cruzado, poca. Si haces tus programas desde cero con un programa ensamblador, éste se encargará de la conversión de instrucciones estándar a opcodes, aunque no viene mal conocer la existencia de estas instrucciones. Para los programadores de emuladores y de desensambladores, el conocimiento de estos opcodes es vital.El juego Sabre Wulf, por ejemplo, utiliza una de estas instrucciones en la determinación del camino de uno de los enemigos en pantalla (la instrucción SLL, que veremos a continuación), hasta el punto en que los primeros emuladores de Spectrum emulaban mal este juego hasta que incluyeron dicha instrucción en la emulación. Los "undocumented opcodes" son esencialmente opcodes con prefijos CB, ED, DD o FD que hacen unas determinadas operaciones y que no están incluídos en la "lista oficial" que hemos visto hasta ahora. Todos los ejemplos que veremos a continuación están extraídos del documento "The Undocumented Z80 Documented", de Sean Young. Prefijo CB Por ejemplo, los opcodes CB 30, CB 31, CB 32, CB 33, CB 34, CB 35, CB 36 y CB 37 definen una nueva instrucción: SLL.
SLL (Shift Logical Left) funciona exactamente igual que SLA salvo porque pone a 1 el bit 0 (mientras que SLA lo ponía a 0). Prefijos DD y FD En general, una instrucción precedida por el opcode DD se ejecuta igual que sin él excepto por las siguientes reglas:
Por ejemplo:
El caso de FD es exactamente igual que el de DD, pero usando el registro IY en lugar del IX. Prefijo ED Hay una gran cantidad de instrucciones ED XX indocumentadas. Muchos de ellos realizan la misma función que sus equivalentes sin ED delante, mientras que otros simplemente son leídos y decodificados, resultando, a niveles prácticos, equivalentes a 2 instrucciones NOP. Veamos algunos de ellos:
Aparte de los duplicados de NOP, NEG, IM0, etc, podemos ver un par de instrucciones curiosas y que nos pueden ser de utilidad. Por ejemplo:
Esta instrucción lee el puerto C, pero no almacena el resultado de la lectura en ningún lugar. No obstante, altera los flags del registro F como corresponde al resultado leído. Puede ser interesante si sólo nos interesa, por ejemplo, si el valor leído es cero o no (flag Z), y no queremos perder un registro para almacenar el resultado. Prefijos DDCB y FDCB Las instrucciones DDCB y FDCB no documentadas almacenan el resultado de la operación de la instrucción equivalente sin prefijo (si existe dicho resultado) en uno de los registros de propósito general: B, C, D, E, H, L, ninguno o A, según los 3 bits más bajos del último byte del opcode (000=B, 001=C, 010=D, etc). Así, supongamos el siguiente opcode sí documentado:
Si hacemos los 3 últimos bits de dicho opcode 010 (010), el resultado de la operación se copia al registro D (010 = D en nuestra definición anterior), con lo que realmente, en lugar de "RLC (IX+01h)" se ejecuta:
La notación que sugiere Sean Young para estos opcodes es: "RLC (IX+01h), D". Con el prefijo FDCB ocurre igual que con DDCB, salvo que se usa el registro IY en lugar de IX. De la teoria a la practica Con este capítulo hemos cubierto el 99% de las instrucciones soportadas por el microprocesador Z80. Con la excepción de los Modos de Interrupciones del Z80 y sus aplicaciones, ya tenemos a nuestra disposición las piezas básicas para formar cualquier programa o rutina en ensamblador. No obstante, todavía quedan por delante muchas horas de programación para dominar este lenguaje, así como diferentes técnicas, trucos, rutinas y mapas de memoria que nos permitan dibujar nuestros gráficos, realizar rutinas complejas, utilizar el sistema de interrupciones del microprocesador para realizar controles de temporización de nuestros programas, o reproducir sonido. FICHEROS
LINKS
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Santiago Romero |

| 2003-2009 Magazine ZX |